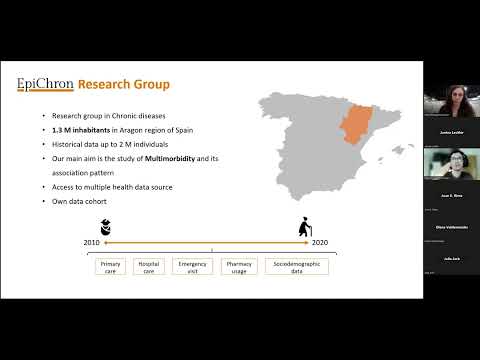
[0:00]to today's, uh, uh, to today's webinar hosted by VACCELERATE, uh, which is focusing on, um, health and vaccine safety research using real-world data. As Janine said, please keep your cameras and microphones off during the webinar and for any questions, please add them in the chat and there will be some time for a Q&A session after Alejandro's presentation. Um, before we start, I would like just to share a couple of, um, reflections, uh, on the topic that we are addressing today. Um, so real world world data in general refers to information that is collected from various sources in the routine course of patient care. Uh, it can be electronic health records, or it can be claims data, or it can derive from patient registries and more recently, also from wearable devices like our smart watches, for example. Um, especially over, uh, the last decade, it has become a hot topic, the use of real-world data for research. Um, especially now with the developments around the European Health Data Space, uh, it's gaining increasing attention from different policy makers, uh, from funders, but also from regulatory authorities. The FDA, the EMA are, uh, running projects like the Darwin project, which is focusing on, uh, why such data is valuable for research. Uh, for example, real world data can complement results from clinical trials, uh, from traditional clinical trials, for example, improve, improve the, um, inclusivity and generalizability of the results. Uh, or, uh, help us include, um, people that have different demographic characteristic or, uh, varying levels of adherence to to treatment of, um, specific drugs. And also, it allows us to have longer follow-up periods than the classical, uh, shorter term clinical trials and include a larger, um, sample size. Uh, so we will hear much more on this, uh, on what is happening in the EX, the Instituto Aragones de Ciencias de la Salud in Zaragoza, Spain, uh, from the speaker of today, Alejandro Santos Mejías, who is working as a bioinformatician and public health data analyst. Uh, so Alejandro will explain us what the research in Epic Chron, the group that he's working on, and the floor is yours, Alejandro. Okay, thank you a lot, Maria, you have helped me a lot with the introduction because I will mention probably many of the things that you have already mentioned. So I have no conflict of interest to disclose right now. And as I, as you tell, right now there is an increasing interest in the European Union to make more available the real-world data that are constantly being generated in the clinical practice. For example, the Darwin, the Darwin initiative that try to create a unified catalogue of these data sources to know in which part of Europe you can access the information that you need for your study in particular. And also not only that, but they wanted to create this a common data model to work similarly in every data source, so you can have access always complying with the data protection law, but allowing at least to have real-world data study in an easiest way, in the easiest way possible. Not only that, uh, you mentioned the European data space that that the main objective of this initiative is to create the framework, the legal framework. So this reality that is, uh, that every day thousand and thousand of million of clinical data is being generated. This data could be, uh, legally useful and they can be accessible to for that, there has to be an establishment of common data, common standards and practices. But working with real-world data and in a randomized clinical trials, it's not the same. They have differences. For example, the main one is the scope, the nature of these two approaches. Randomized clinical trials, they try to work with the unknown. We do not yet know with what does health safety can be assessed in this medicinal product, particularly, so they are the cold standard. They work in a very small subset of people with a high homogeneity and in a controlled way. That's totally the opposite of real-world data. These, uh, the data from these studies came from the clinical practice, so you cannot control how this data is generated or the missingness or the completeness of these, uh, of this useful information. And as you mentioned, it is true that randomized clinical trials, due to their settings, they do not find themselves capable of capturing long-term outcomes, but this can be helped and filled with the, with a basic, with a basic design of real-world data studies. The second, uh, the second main difference is that I want to mention is the study design itself. Cohorts in randomized clinical trials, they tend to be small and quite homogeneous. That doesn't happen usually in real-world data studies. They tend to be huge. We are talking about millions as basic and they tend to assess reality itself, and reality is complex with multiple pathologies, with subgroups that cannot be sometimes accessed in randomized clinical trials like immunocompromised people, pregnancy women, they are hard to, to work with. So the inclusion criteria, inclusion and exclusion criteria, they tend to be less restrictive in random, in real-world data studies than in randomized clinical trials. Also the last differences that I want to mention is the cost, because real-world data tend to cost less to be implemented and they are easier to implement in a long, in a longer term. So with the same quantity of money, just to say that, uh, you can perform a longer studies with these, uh, real-world data approach. So I just wanted to give you the message that post-authorization safety study that because it's another way of calling real-world data studies, uh, should be seen as complementary to randomized clinical trials, because they work for the same to understand how the treatment, how this medicinal product, vaccines in our case, uh, is behaving in the complex reality. But working with real-world data can be challenging, above all when we are talking about data quality and data completeness. Uh, most of the variables that we are interested, for example, clinical variables like diagnosis, procedures, use of services, treatments, they tend to be trustful and with very low missingness. But, uh, this happened because these, uh, variables are useful for the clinical practice. They need to be that way. But other variables that are not so useful or are not imposed by law that they have to be recorded, like for example, sex, age, country of birth, uh, they lack this, uh, fidelity, this trust, this trustiness. For example, lifestyle variable, what we have seen in my group is that most of the time they are missing and when they are not missing, they are not up to date, for example, the smoking status. It, it only updated when the clinician, the general practitioner, remember that they have to ask sometimes that, are you a smoker? How many cigarettes per day do you smoke? And so on, or, for example, clinical variables, uh, some clinical variables, even so they are systematically recorded, they are not accessible yet in some system, in some health system, like imaging results, depending on the area, cannot be extracted. And then we have some kind of special cases that some epidemiology groups work with is environmental environments, environmental variables that they are not missing and they are trustful. The information that they, uh, recorded is worth it, but they do not tend to be connected to the health automatic system. So they require a hard work by the research group to connect those variables with the outcomes that you are studying. Uh, that's hard work can be done by a research group that has the capability and experience as my own group, the Epic Chron research group that, uh, it's centred in the chronic diseases and have access to 1.3 million inhabitants health data from the region of Aragon in the, you can see the region in the map. And historically this data can add up to two million individuals. Our main goal is the study of multimorbidity, that is the coexistence of two or more chronic conditions in the individual. And for that we have access to several data sources, like primary care, hospital care, emergency visits, pharmacy usage and some sociodemographic data. So, we have a lot of the picture, a lot of the information to assess many of the things that a real-world data study requires. For that we have created even our own data cohort that contain almost the, the full population of Aragon, the 82% of citizens from 2010 to 2020 to 2020. And with this cohort, we have been involving, we have been investigating multimorbidity, but why multimorbidity? It's because even so there is not, that's, uh, even so there is a low prevalence in our early life, from zero to 20, 29 years old, it's become the norm, it's become the rule after we pass the 45 year band. So most likely everyone in the population will be multimorbid and they are complex and they are most of the time excluded from randomized clinical trials. And we have seen that in most cases, uh, medicine and treatments, they do not tend to behave the same as an homogeneous and healthy or an homogeneous healthy population. For that, uh, we have been interested in polypharmacy patterns, uh, seeing which kind of treatment are associated to which kind of morbid patterns. In most of the cases, we have seen that they are full with symptomatic treatments that are not essential for the for the treatment of the disease.
[12:11]Also we have been participating in different post-authorization safety studies. In this case, I wanted to mention and illustrate the example of Cilostazol Drug Utilization study. It was a study that was centered in Cilostazol, a platelet aggregation inhibitor that was marketed in Europe for intermittent claudication since 2002, but it has been associated in the past with spontaneous serious bleeding and cardiovascular effects.
[12:51]So the EMA caught, uh, caught that, uh, so that caught the attention of the EMA and it implemented some risk minimization measurement to restrict the use of Cilostazol in certain patients and reduce certain characteristics of Cilostazol patients. That was, uh, performed by changing the summary of product of those characteristics in 2013.
[13:23]And for that, uh, sorry, and for that the EMA requires a drug utilization study before and after the changes. So the objective of this post-authorization safety study was to evaluate the prevalence of new new users of Cilostazol before and after the changes, and the frequency of conditions of this condition targeted by the risk minimization measurements that can be seen in the table in the right. Some of these measurements were just, okay, you have to change your lifestyle, like smoking cessation, because it's useful for your treatment with Cilostazol. And others were more related to the reduction of the use of Cilostazol in certain kind of patients. For that, uh, this study was performed in five health databases in four different countries, two of them in for different countries, two of them were Spanish databases, one the Epic Chron group and the other the SIDAP, the Catalonian one. And the cohort included 2,519 and 1,821 new users of Cilostazol before and after the implementation of this summary product characteristics. So what we have here is that the study will start from the marketed date in each country that varies from 2002 to 2009, uh, to, uh, the 2013 that will be the before period. And in 2004 will be assessed, the after period was assessed. So as you can see, the inclusion criteria are really, I mean, they are they are not many, they are few. Just to have a prescription of Cilostazol during the study period and having at least six months of continuous enrolment in the database. There was no exclusion criteria, so most of the Cilostazol users were were captured during this study. And regarding the results, I just want, I just want to mention two that are really important and visual. The one was that during the first period, the before period, there was an increase usage of Cilostazol until 2012, 2011, depending on the database. And after the changes in this summary of product characteristics, there was a substantial reduction in many of the databases, so the changes were useful and successful in reducing the prevalence of new of new users. Also, we measured if there were changes, at least a 5% changes in the characteristic that the EMA was interested in. And in many of them, there was a positive change, so they were improved after these changes of summary product. In 2019, the the vaccine monitoring collaboration for Europe network was created and we are part of that, that's why we are now involving in vaccine post-authorization safety studies. These, uh, this network is a non-profit network specialized in collaborative generation of vaccine real-world evidence on mostly to cover to assess coverage, safety and effectiveness. It was created during the COVID, so as you can imagine most of the of the study has been COVID-19 related, but any kind of vaccine can undergo the the scope of this network. There are 27 members across Europe and 15 health care data sources covering more or less 150 million citizens. So we have plenty of information to work with. We have successfully participated in four public tenders and four post-authorization EMA regulatory safety studies on COVID-19 vaccines, but eventually in the future will be a more diverse portfolio. So the way of creating, the way of starting a project in this network is the following. First, firstly, uh, study requester, that normally is the EMA, propose a research question, uh, regarding vaccines. It could be also a pharma company, like Jansen and Johnson, Pfizer, whatsoever. Then the secretariat evaluate this proposal, if there is availability of the data and the question is feasible to be answered with the, with the power that we are actually that we currently are in the in the network. If the feasibility assessment is all right, then an open call for the for the rest of members are established, and everyone that wanted to participate can participate in the study group. Uh, then the study group and the coordination team, it's, uh, created, and, uh, protocol development, uh, and the protocol development begins. Most of the time, we work in this data workflow. We start with the original data, we have this original data goes through an ETL process that you have to establish, uh, an, uh, identify, uh, specified, well, better said, specified which variable of your original data are going to be transformed in which variable of the common data model. This transformed data undergoes through several level checks to check that, okay, the data that you have transformed, follow the structure of the common data model. It is completed, anno missingness in the important variable that you are interested is presented. If everything is all right, these data are considered validated for the common data model that we use the conception common data model that is an open an open source, free and academic common data model that everyone can implement in the data sources. And after that, we run the, the analysis scripts that are tailored to answer the research question of every project.
[20:30]We retrieve some interim report, some preliminary results. In many of the projects, this kind of way, this kind of work, it's iterative. It's, uh, there's not going to be just one interim report. There are going to be multiple and in this kind of loops, the process will be improved, no matter if it is in the analysis or in the level checks or maybe the EMA make an amendment and wanted to increase or add another adverse event whatsoever. This process is alive and it's constantly improving during the the project. Finally, when we have our final results, a meta-analysis of the different participants and results are performed and we retrieve a summary report that is completely open and public. Everyone can check it. So we are part of the post-conditional approval active surveillance study among individuals in Europe receiving the Pfizer-BioNTech coronavirus disease 2019 (COVID-19) vaccine, in other words, a post-authorization safety study of the COVID vaccine.
[21:50]So, uh, the objective of this study was to determine increased risk of some special of some adverse event of special interest. This, uh, after the administration of at least one dose of the COVID-19 vaccine. These adverse event of special interest were established in project before, because of the relevancy of lethality or the relevancy of, uh, the development of new borns. And most of them are quite, uh, quite burden on health, like myocarditis, pericarditis, uh, Guillain-Barré, or, uh, fetal, uh, fetal abortion and so on. Or there can be a little bit lighter like secondary menorrhea or dysmenorrhea, etcetera, etcetera. The second objective was to estimate the incidence rates of adverse event of special interest among subpopulation. In this case, the pregnancy cohort was conformed. And thirdly, the the last aim, the last objective was to to assess, uh, utilization patterns along different subcohorts, immunocompromised people, elderly and, uh, subject with some specific comorbidities. With that in mind, this project is actually, is currently running in eight different data sources from five different countries. It's a non-interventional retrospective cohort study and the study period, uh, was from 2021 to almost right now 2023. We are finishing it yet.
[23:44]In this case, there are more inclusion and exclusion criteria. For instance, we have, uh, asked always, we have selected only subjects that has a minimum of 12 months of active enrolment to ensure that the information is trustful and useful. That there are no history of COVID before the first vaccination, the date of vaccination. And that those subject for the subpopulation analysis, uh, were were fulfilling the requirement to fulfill the requirements to be considered for those population analysis. If they are, if they are going to be part of the pregnant cohort, they have to be pregnant women. If they are elderly, they have to be of certain age and so on. The the exclusion criteria, the only exclusion criteria that we established was to not having a diagnosis of any kind of of any of the adverse event of special interest under study within one year before the vaccination date. So we take out all these kind of subjects that already have these diseases. For that we perform we are performing a rollout cohort design using a matching process of one to one.
[25:10]In this matching process, what we try is to match any vaccinated subject with any unvaccinated subject that share similar characteristics by age, by sex, by any kind of other matching characteristics. But some scenario scenarios could happen in the way that, for example, imagine that the first person is the case person, and is vaccinated, there will be a match of this person with another subject that share similar characteristics. And it's already not unvaccinated, but if during the study period, this second person, the control one, is vaccinated, this two couple, this matched couple will be censored and another matching procedure will be performed to match these two vaccinated people. Another scenario that could happen is that the vaccinated, a vaccinated subject, get disenrolled of the database because he abandoned the health system. In that case, this match couple will be totally dismissed and will be no will be not considered for further analysis. And lastly, we will have the last case in which the person that is vaccinated, reached the time of analysis. But the control do not reach this analysis because it get an outcome. So, uh, in this case, the match will stop there, but this, uh, couple will be, uh, will be used for the for further analysis later on. Also, as a sensitivity analysis, for this project in particular, we have been using a self-control risk interval design. What does it mean? Well, for some adverse event that, uh, do they have a very well-known risk window and are acute, uh, patients that are vaccinated, will be, uh, will be as will be analysed to see if in those risk Windows, they have increased risk to to, uh, will have an increased risk that that those adverse event happens. In comparison with a control period that it will be a longer time and after this risk event. So I cannot show you yet any kind of result, but it's the way of working that is quite easy and straightforward, uh, fitting with the way of with the way of you with the way of you working. And you have access to several data sources, you can always join VACCELERATE, so now I'm happy to answer any kind of your questions.
[28:21]Okay, thanks, Alejandro. And there is one question in the chat.
[28:29]Uh, so Julia is asking which barriers do you see as most challenging in conducting multinational real-world studies? And she says, I can imagine that national real-world data databases differ already widely, especially in a country like Spain that you are rather regional, I would say, you have a more regional approach. And, uh, how can this issue be addressed in such studies? So which barriers and how do you think they can be addressed? Well, uh, of course there are many barriers, in fact in Spain, the the way that we work real-world data in Aragon is totally different from, for example, Catalonia or Andalusia. Uh, so most of the barrier is the way variables information is recorded.
[29:26]Some data sources use different code systems, so you have to take that into account in order to map those code systems and make an equivalent meaningful reasoning between those. And also, uh, the importance that different health systems, uh, give to different information, for example, here smoking status that it's uh, the key element in my head right now, it's recorded in a way that it's not recorded, for example, in Germany. In Germany, they do not tend to ask how many cigarettes per day do you have. They just, uh, ask you if you are smoker or not.
[30:07]So you have to work very, uh, very closely with the research team in order to assess and evaluate the necessities of your own context. For making these equivalences.
[30:25]Okay, thanks.
[30:28]And I would have another question, especially for your COVID study. You mentioned that you started the cohort, it was a prospective cohort and you started it in 2021 and you are still recruiting, because you mentioned 2023. Yeah, we are following up. We are following up. Following up. Okay.
[30:49]We are not, I mean, in real-world data, we do not recruit the, the data. It's already generated, so we just extract it from the electronic health. EHR. Yeah, okay. Okay.
[31:12]And, uh, one last question from me and then if you have other questions for the participants, please feel free to put them in the chat. You mentioned that, uh, in back for you, uh, you are contacted by the EMA or by pharma companies with specific questions. Do you then work closely with them afterwards for defining, uh, I don't know, inclusion, exclusion criteria that they want or the real research question or are they just coming with a question to you and then you are independently assessing? Uh, it depends on the ad on the outcome that they want to measure, but in most of the cases, we work complementarily. We we work closely to to them. But as a data access provider, as a an an an analyst point, uh, we do not tend to have to deal with this kind of, uh, of problems. They do it in the in the secretariat level or in the coordination team level. Mhm.


